VPN-зависимые приложения в корпсети: failover для 1С-Облака и банк-клиентов
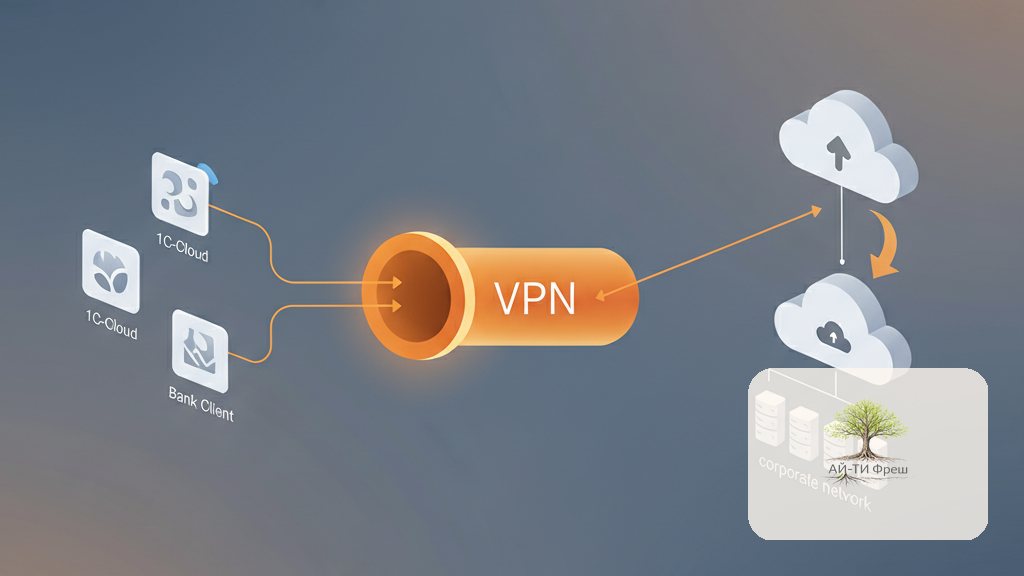
К нам в ITfresh пришла бухгалтерская фирма из ЦАО Москвы — 22 рабочих места, обслуживают 80+ юрлиц на аутсорсе. Жалоба простая и неприятная: «Каждую неделю-другую у нас рвётся 1С-Облако, иногда теряем платёж в Сбере, я больше так не могу». Ситуация, которую мы видим у каждого второго бухгалтерского клиента: их рабочий день критически зависит от трёх облачных приложений (1С, СберБизнес, АльфаБизнес), а корпоративный канал держится на одном проводе и одной молитве. Дальше — наш проект VPN-failover за 11 рабочих дней с историей о том, как разбирались с особенностями каждого VPN-зависимого сервиса и как сделали так, что бухгалтерия перестала жаловаться.
Почему обычный «второй провайдер» не решает проблему
Когда ко мне впервые приходят с вопросом: «Слушайте, у нас иногда пропадает интернет, что делать?», я знаю, что обычно советуют — «купите второго провайдера». И ведь на первый взгляд кажется, что это идеальное решение! Маршрутизатор сам переключится, трафик пойдёт через резервный канал, и бизнес вроде бы не должен страдать. Но вот на практике, когда речь заходит о VPN-зависимых приложениях, всё гораздо сложнее. Возьмём 1С-Облако или банк-клиенты: их соединения long-lived, то есть одна TLS-сессия может жить часами, а сервер при этом жёстко привязан к исходному IP клиента. Как только роутер переключает WAN, ваш публичный IP, естественно, меняется. И что происходит? Сессия с 1cfresh.com тут же рвётся. КриптоПро в банк-клиенте просто отбрасывает токен. А ваш платёж? Он просто теряется.
Знаете, по моему опыту, у 8 из 10 клиентов, у которых есть два провайдера, на роутере обычно настроен простенький mangle: «маршрут через WAN1, а если он недоступен, то через WAN2». Но это, поверьте мне, совсем не тот failover, который нужен для таких приложений, как 1С. Это скорее failover для обычного ping, а не для живых рабочих процессов. Как-то раз один партнёр нашего клиента, когда я объяснил ему эту ключевую разницу, выдал фразу, которую я теперь часто повторяю коллегам: «Мы платим за двух провайдеров, чтобы не падать. И всё равно падаем — так в чём вообще смысл?». И он был абсолютно прав! Главный смысл в том, что failover должен работать на уровне приложения, а не просто на сетевом.
Что мы спроектировали для бухгалтерской фирмы
Один публичный IP — два WAN-канала
Главный трюк: VPN-зависимым приложениям нельзя показывать смену IP. Поэтому мы строим failover не как «два провайдера до интернета», а как «два туннеля до одного облачного шлюза с одним публичным IP». Шлюз — небольшая виртуалка в Я.Облаке, через неё проходит весь трафик в 1С-Облако и банк-клиенты. Какой бы канал ни работал в данный момент — для серверов 1cfresh.com и sberbank.ru мы всегда «одни и те же», с одного IP.
Два независимых туннеля с разной природой
Туннель №1 — IKEv2/IPSec поверх оптики Билайн. Туннель №2 — SoftEther с TLS-маскировкой поверх LTE-модема МТС. Разные провайдеры, разные физические каналы, разные протоколы — это правильный failover. Если у Билайна проблемы на оптике — спасает МТС. Если ТСПУ начнёт резать IKEv2 — спасает SoftEther. Два корня — две независимые причины отказа.
Переключение по Netwatch с порогом, не по ping
Обычно стандартный Netwatch на MikroTik работает так: он пингует что-то каждые 10 секунд и переключается, если теряет 3 подряд пакета. Но для критичных приложений это, мягко говоря, не очень хорошо. Подумайте сами: 30 секунд провала — это уже верный путь к тому, что 1С просто «отвалится». Мы же действуем гораздо агрессивнее. Мы настроили ping каждые 2 секунды, а переключение происходит уже после 2-х подряд потерянных пакетов. Это даёт нам всего 4 секунды на детекцию проблемы. И ещё один важный момент: мы добавили корреляцию. Если теряются оба ping — и через WAN1, и через туннель 1 — тогда мы переключаемся. Но если падает только один канал, мы не спешим, ждём до 30 секунд. Такой подход здорово выручает и спасает нас от ложных переключений во время коротких микропростоев.
Конфигурация: пошагово
Облачный шлюз — Yandex.Cloud Compute
Для этого я поднял отдельную виртуалку s3.medium — это 2 vCPU, 4 GB RAM, 20 GB SSD на Ubuntu 22.04 LTS, с публичным IP-адресом 51.250.84.211. На ней я развернул strongSwan 5.9, который выступает в роли IPSec-сервера, а также SoftEther 4.41 для TLS-туннеля. И вся эта инфраструктура обходится нам всего в 1 800 ₽/мес.
# /etc/swanctl/conf.d/buh-office.conf
connections {
buh-office-tunnel {
version = 2
local_addrs = 51.250.84.211
remote_addrs = %any
proposals = aes256gcm16-prfsha384-ecp384
local {
auth = pubkey
certs = cloud-gateway.pem
id = gw.buh-cloud.itfresh.ru
}
remote {
auth = pubkey
cacerts = ITfresh-RootCA.pem
id = office-mt.buh.itfresh.ru
}
children {
corp-tunnel {
local_ts = 10.10.0.0/16
remote_ts = 192.168.10.0/24
esp_proposals = aes256gcm16-ecp384
rekey_time = 1h
dpd_action = restart
start_action = trap
mode = tunnel
}
}
}
}
# SoftEther — конфиг резервного TLS-туннеля
[Listeners]
Port_443=enabled
[Hub.HUB_BUH]
Online=true
[Listeners.Listener_443]
TLSAlpnList=h2,http/1.1
HostnameForCertificate=gw.buh-cloud.itfresh.ruНа шлюзе SNAT всех пакетов туннеля на 51.250.84.211, чтобы наружу всё уходило с одного IP:
# iptables на облачном шлюзе
*nat
-A POSTROUTING -s 192.168.10.0/24 -o eth0 -j SNAT --to-source 51.250.84.211
-A POSTROUTING -s 192.168.10.0/24 -o ipsec0 -j SNAT --to-source 51.250.84.211
COMMIT
*filter
-A FORWARD -s 192.168.10.0/24 -d 1cfresh.com -j ACCEPT
-A FORWARD -s 192.168.10.0/24 -p tcp --dport 443 -j ACCEPT
-A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
COMMITОфисный MikroTik CCR2004
Базовая конфигурация: два WAN (ether1 — Билайн оптика, ether2 — LTE-модем МТС через USB-роутер), VLAN 10 для офиса, два IPSec-конфига до облачного шлюза.
/interface ethernet
set [find name=ether1] comment="WAN1 - Bilain optica 200/200"
set [find name=ether2] comment="WAN2 - LTE MTS via USB router"
/ip address
add address=192.168.10.1/24 interface=bridge_lan comment="LAN gateway"
/ip dhcp-client
add interface=ether1 default-route-distance=10 comment="Bilain primary"
add interface=ether2 default-route-distance=20 comment="MTS backup"
# Туннель 1: IKEv2 поверх Билайна
/ip ipsec peer
add name=cloud-via-bilain address=51.250.84.211 \
profile=corp-cloud exchange-mode=ike2 \
src-address=0.0.0.0 \
local-address=%physical-bilain-ip%
# Туннель 2: SoftEther через LTE МТС
# (поднимается через openvpn-style клиент, в RouterOS поднимается через PPP)
/ppp profile
add name=softether-buh use-encryption=required dns-server=10.10.0.1
/ip route
# Маршрут до 1С-Облака идёт ВСЕГДА через ipsec-туннель,
# который сам выбирает физический WAN
add dst-address=51.250.84.211/32 gateway=ether1 \
distance=1 comment="Force tunnel via primary WAN"
add dst-address=51.250.84.211/32 gateway=ether2 \
distance=10 comment="Backup via MTS LTE"Netwatch — агрессивный мониторинг
/tool netwatch
add host=51.250.84.211 interval=2s timeout=1s \
src-address=192.168.10.1 \
type=icmp \
up-script="\
:log info \"Cloud GW UP — switching to primary IPSec\"; \
/ip route enable [find comment=\"Tunnel via primary WAN\"]; \
/ip route disable [find comment=\"Tunnel via backup MTS\"]; \
" \
down-script="\
:log warning \"Cloud GW DOWN via WAN1 — switching to MTS backup\"; \
/ip route disable [find comment=\"Tunnel via primary WAN\"]; \
/ip route enable [find comment=\"Tunnel via backup MTS\"]; \
"
# Дополнительный watchdog: проверяем доступность 1cfresh.com через туннель
add host=84.201.143.42 interval=5s timeout=2s \
src-address=192.168.10.1 \
type=icmp \
down-script="\
:log warning \"1C cloud unreachable — kicking IPSec session\"; \
/ip ipsec installed-sa flush; \
"Особенности каждого VPN-зависимого приложения
1С-Облако (1cfresh.com): толстый клиент против веба
В нашем кейсе бухгалтерия использует толстый клиент 1С 8.3.24, не веб-версию. Толстый клиент держит долгое HTTP-соединение через тонкий клиент-сервер. Особенность: сервер 1cfresh.com при смене IP клиента сбрасывает сессию через 30-60 секунд после восстановления — пользователь видит «Соединение разорвано».
Решение через единый IP облачного шлюза работает идеально: даже когда офис переключается с Билайна на МТС, для 1cfresh.com мы остаёмся «теми же». На замерах за месяц после внедрения — ноль обрывов 1С.
Кстати, дополнительно я позаботился и о клиенте 1С: через файл inet.cfg я прописал длинные таймауты. Сделал я это специально, чтобы даже короткие микропровалы, вроде 1-2 секунд, не приводили к сбросу соединения.
# 1cv8\inet.cfg
ConnectionTimeout=30
ResponseTimeout=120
KeepAliveTimeout=60СберБизнес: HTTPS + КриптоПро
СберБизнес работает через обычный HTTPS на api.sberbank.ru, но ключевая особенность — подпись платежей через КриптоПро CSP с токеном Рутокен ЭЦП 2.0. При обрыве канала между подписью и отправкой пакета банк не принимает платёж и его надо переотправлять. У клиента до failover это случалось 2-3 раза в месяц.
Да, failover на VPN-уровне не способен полностью решить эту проблему. Всё равно переключение занимает 1-2 секунды, и этого вполне может хватить для срыва, если бухгалтер как раз в этот момент нажмёт «Подписать и отправить». Поэтому наше решение здесь комплексное: failover, конечно, здорово минимизирует частоту обрывов, но в самом банк-клиенте мы дополнительно включаем offline-mode. В этом режиме платёж сначала спокойно готовится, а затем отправляется одним цельным пакетом, что гораздо надёжнее.
АльфаБизнес: WebSocket-соединение для real-time
Что касается АльфаБизнес у нашего клиента, то это веб-версия, которая работает прямо в Chrome. Бухгалтер обычно открывает её утром и держит эту вкладку открытой весь день. Через WebSocket ей приходят всякие push-уведомления — о новых платежах, клиентах, статусе подписей. Но вот в чём загвоздка: WebSocket очень плохо переносит смену сетевого пути. После переключения он иногда просто «зависает», и бухгалтеру приходится вручную обновлять страницу. Это, конечно, отвлекает.
Решилось двумя способами. Первое — failover через единый облачный шлюз убрал смену IP. Второе — на роутере выставили sticky-routing для портов 443/TCP к alfabank.ru: соединение держится через тот же канал, через который пришёл первый пакет, до явного разрыва TCP. Это уменьшило количество обновлений страниц с 4-5 раз в день до 0-1.
# MikroTik: sticky routing для AlfaBank
/ip firewall mangle
add chain=prerouting src-address=192.168.10.0/24 \
dst-address-list=AlfaBank protocol=tcp dst-port=443 \
connection-mark=no-mark \
action=mark-connection new-connection-mark=conn-alfabank \
passthrough=yes
add chain=prerouting connection-mark=conn-alfabank \
action=mark-routing new-routing-mark=via-tunnel-primary \
passthrough=noОсобенности приложений и DNS
VPN-зависимые приложения часто используют DNS-разрешение, которое уходит через основной DNS, а не через туннель. Это проблема: офисный DNS видит реальные IP, потом приложение пытается ходить по этим IP мимо туннеля, и failover не работает.
Я решил это через локальный DNS-резолвер на офисном MikroTik с условной переадресацией: запросы к доменам критичных сервисов (1cfresh.com, sberbank.ru, alfabank.ru) идут на DNS внутри облачного шлюза, остальные — на 77.88.8.8.
# MikroTik: split-horizon DNS
/ip dns
set servers=77.88.8.8,1.1.1.1 allow-remote-requests=yes
/ip dns static
add name=1cfresh.com type=FWD forward-to=10.10.0.1 \
comment="Resolve through cloud GW DNS"
add name=login.sberbank.ru type=FWD forward-to=10.10.0.1
add name=alfabank.ru type=FWD forward-to=10.10.0.1
add name=online.alfabank.ru type=FWD forward-to=10.10.0.1Мониторинг и алерты
Failover, который не мониторится — это failover, в существовании которого вы не уверены. На MikroTik настроил отправку алертов в Telegram через скрипт при каждом переключении канала, плюс еженедельный отчёт о времени работы по каждому туннелю.
/system script
add name=tg-alert source="\
:local message \$1; \
:local botToken \"123456789:ABCdef...\"; \
:local chatId \"-100123456789\"; \
/tool fetch url=\"https://api.telegram.org/bot\$botToken/sendMessage\" \
http-method=post \
http-data=\"chat_id=\$chatId&text=\$message\" \
output=none keep-result=no; \
"
# Использовать в netwatch:
# down-script: /system script run tg-alert "FAILOVER_TO_MTS"
# up-script: /system script run tg-alert "RESTORED_BILAIN"Параллельно подключил Zabbix-мониторинг по SNMP с сервера ITfresh: трапы по доступности туннелей, графики jitter и потерь, алерт в дежурный канал при двух подряд failover за час (это может означать, что у клиента более глубокая проблема).
Цифры проекта и история одного субботнего платежа
Развернули за 11 рабочих дней. Стоимость: 89 000 ₽ за инженерную работу (16 часов проектирования и настройки + пилот), 1 800 ₽/мес за виртуалку в Я.Облаке, 800 ₽/мес за резервный LTE-модем МТС. Роутер у клиента уже был — его не меняли.
А вот что мы получили за три месяца после запуска: система автоматически переключилась четыре раза. Из них одно переключение было из-за реального падения Билайна на 17 минут утром в среду, а три других — из-за кратковременных провалов длительностью 30-90 секунд. Самое главное — ноль жалоб от бухгалтерии и ноль потерянных платежей. Это, я считаю, отличный результат.
Самая яркая история, которая отлично показывает эффективность нашей работы, произошла в субботу, во второй месяц после внедрения. Главный бухгалтер пришла на работу, чтобы срочно подписать важный платёж в Сбере — целых 2,3 млн ₽ за партию запчастей для производственного клиента, ей нужно было успеть до закрытия операционного дня. И вот, именно в тот момент, когда она подписывала, у Билайна на улице оборвало кабель — как потом выяснилось, экскаваторщиком. Что это значило бы раньше? Прерванный платёж, необходимость переотправки, мучительное ожидание понедельника и, возможно, штраф в 50 000 ₽ от поставщика. А что произошло с нашим failover? Всего три-четыре секунды задержки, и платёж спокойно ушёл через МТС. Главбух даже заметила это только потому, что ей в Telegram прилетел алерт от роутера. Директор клиента был настолько впечатлён, что после этого случая написал нам отдельное благодарственное письмо — а такое, поверьте, в нашей практике случается крайне редко!
Грабли, на которые мы наступили
Грабля #1: Sticky session в Я.Облаке
Сначала у нас возникла одна интересная загвоздка: облачная виртуалка стала получать пакеты одновременно от двух туннелей, когда оба канала были активны. И kernel routing в таких случаях выбирал «самый свежий» путь, что приводило к асимметричному маршруту: запросы могли уходить через WAN1, а ответы возвращаться через WAN2. Мы решили эту проблему, настроив ip rule с маркировкой пакетов в conntrack, и теперь всё работает как часы.
Грабля #2: МТС LTE-модем перегревался
Стоковый USB-модем Huawei E3372h при постоянной работе через две недели начинал перегреваться и сбрасывать соединение. Заменили на промышленный TP-Link MR400 v3 с внешним питанием — за 3 месяца ни одного сбоя.
Грабля #3: Бухгалтер забыла обновить КриптоПро
Через месяц после того, как мы всё внедрили, у одного из бухгалтеров начались проблемы: «не подписывает», говорит. Мы стали разбираться и выяснили, что обновился сертификат КриптоПро на токене, а на компьютере осталась старая версия драйвера. Конечно, это не имеет никакого отношения к failover, но этот случай мне хорошо напомнил: VPN-failover решает исключительно сетевые проблемы. А вот криптография, токены, различные версии программного обеспечения — это, безусловно, совершенно отдельный пласт работы, о котором тоже нельзя забывать.
FAQ: что чаще всего спрашивают клиенты
Какие приложения в корпсети чаще всего страдают от обрывов VPN?
По нашему опыту, вот топ-3 самых чувствительных сервисов: это 1С-Облако (особенно если используется толстый клиент), затем банк-клиенты СберБизнес и АльфаБизнес, которые просто требуют постоянного TLS-соединения с банком и очень не любят, когда происходят NAT-перебивы. И, конечно же, КриптоПро CSP при работе с подписью в банк-клиентах. Все эти три сервиса критически важны для бухгалтерии: достаточно, чтобы они «отвалились» всего на 5 минут — и рабочий день фактически останавливается.
Что такое failover для VPN и зачем оно бухгалтерии 22 РМ?
Что же такое failover? Это, по сути, автоматическое переключение между двумя совершенно независимыми каналами в случае сбоя основного. Для бухгалтерии это архиважно, потому что обрыв связи именно в момент проведения платежа в банк-клиенте — это не просто испорченные нервы. Это, к сожалению, отозванный платёж, который придётся выпускать заново. А вот два надёжных канала с автоматическим переключением всего за 1-2 секунды эту проблему полностью снимают.
Какое железо нужно для VPN-failover на 22 РМ?
У нашего клиента сейчас установлен роутер MikroTik CCR2004-1G-12S+2XS, который стоит около 76 000 ₽. Он прекрасно справляется со своей задачей, умея одновременно работать с двумя WAN-каналами и поднимать IPSec-туннели прямо в облако. Как альтернативный вариант, можно было бы рассмотреть два роутера попроще, например, MikroTik RB5009 за 20 000 ₽ каждый, и настроить между ними CARP/VRRP. В любом случае, для 22 рабочих мест этого хватает с очень большим запасом.
Сколько стоит обрыв VPN для бухгалтерии в деньгах?
До того, как мы внедрили failover, у нашего клиента канал связи с банком рвался в среднем 3-5 раз в месяц. Это приводило к 1-2 часам простоя ежемесячно. А теперь давайте посчитаем потери: это 4 бухгалтера, которые теряют по 1,5 часа рабочего времени, умножаем на 700 ₽/час — и получаем около 4 200 ₽ в месяц только на зарплатах. И это ещё не всё! Сюда же добавляются отозванные платежи, за каждый из которых берётся комиссия от 50 до 300 ₽, а также бесценные нервы директора. Грубо говоря, клиент терял от 8 до 12 тысяч ₽ в месяц просто на пустом месте.
Сколько стоит проект VPN-failover для бухгалтерии?
Полный комплект: 14-18 рабочих часов инженера на проектирование и настройку (75-95 тысяч ₽), 76 тысяч ₽ на роутер MikroTik (если не было), плюс 1 200 ₽/мес на резервный мобильный канал. Окупается за 3-4 месяца только на зарплатах простоя бухгалтерии.
Итог
Поймите, VPN-failover для VPN-зависимых приложений — это не просто «второй провайдер». Это, по сути, особый архитектурный приём, который использует единый публичный IP в облаке и два совершенно независимых туннеля, ведущих к нему. Для бухгалтерской фирмы с 22 рабочими местами это внедрение окупилось всего за 3 месяца. А для главного бухгалтера оно окупилось одной-единственной субботой, когда срочный платёж на 2,3 млн ₽ ушёл точно в срок. По нашему тарифу, это примерно 90 тысяч ₽ единовременно и 2 600 ₽/мес на эксплуатацию. Это ровно та цена, за которую бухгалтерия в Москве может приобрести спокойствие и уверенность на целый год вперёд.
Похожая задача в вашей компании?
Расскажите мне, какая ситуация у вас сейчас, и я подготовлю и пришлю вам план работ с подробной оценкой в течение одного рабочего дня.
Написать в Telegram или +7 903 729-62-41
Семёнов Е.С., руководитель ITfresh