Миграция Oracle → PostgreSQL без простоя: CDC-схема, которая реально работает
Меня зовут Семёнов Евгений Сергеевич, директор АйТи Фреш. За два последних года к нам пришло пятеро клиентов с одной и той же болью: уйти с Oracle Database на PostgreSQL, не остановив при этом бизнес ни на час. Ни одна миграция не прошла без приключений — в каждой мы наступали на грабли, которым в документации посвящено от силы полтора абзаца. Эта статья — выжимка из реального опыта: что едет в проде, что разваливается на старте и где команды теряют по неделе на ровном месте.
Три стратегии миграции и почему все три больно
По факту подходов три. Перед стартом проекта честно ответьте себе — какой из них вы реально потянете, не по бумаге, а по ресурсам и рискам.
- Офлайн-миграция. Гасите приложение в пятницу вечером, сливаете Oracle в дамп через
ora2pgили expdp+парсер, заливаете в PostgreSQL — к понедельнику запускаетесь. Схема рабочая, если данных до 100 ГБ и система ночью простаивает. Для продовой ERP или биллинга это нереально. - Online через CDC. Поднимаете реплику Oracle → PostgreSQL, она идёт с лагом в несколько секунд, потом переключаете приложение на PG и отключаете Oracle. Лаг создаёт риск потери данных при обрыве — без честного мониторинга и контроля позиции коммитов здесь легко проспать проблему.
- Dual-write + CDC. Приложение пишет сразу в Oracle и PostgreSQL, CDC синхронизирует данные с гарантией, откат — в любой момент. Звучит красиво. На деле: код меняется в двух местах, транзакционности между базами нет, любая рассинхронизация требует ручного вмешательства и остановки прода. Видели проект, где на dual-write угробили три месяца — и вернулись к CDC-only с нуля.
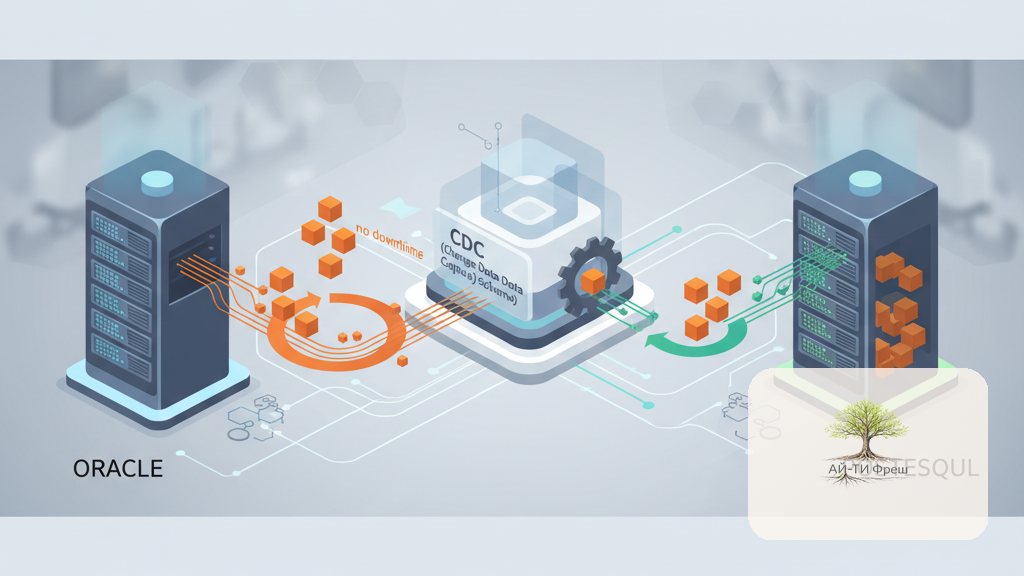
В девяти случаях из десяти выигрывает онлайн через CDC без dual-write. Дальше — как собрать это правильно.
Архитектура: Debezium LogMiner → Kafka → JDBC Sink
Схема, которая реально едет в проде:
- Debezium Source-коннектор с адаптером LogMiner вычитывает redo-логи Oracle и превращает каждую DML-операцию в событие Kafka.
- Kafka держит события в топиках — по одному на таблицу. Порядок внутри топика обеспечивает partition key.
- Debezium JDBC Sink читает из топиков и пишет в PostgreSQL через JDBC в режиме upsert.
Минимальный стек, который мы поднимаем у клиентов:
# docker-compose.yml — минимальный набор
services:
zookeeper: { image: confluentinc/cp-zookeeper:7.5.0 }
kafka: { image: confluentinc/cp-kafka:7.5.0 }
connect: { image: debezium/connect:2.5 }
schema-registry: { image: apicurio/apicurio-registry:2.5 }
kafka-ui: { image: provectuslabs/kafka-ui:latest }
connect-ui:{ image: landoop/kafka-connect-ui:0.9.7 }Debezium или Oracle GoldenGate — вопрос закрывается быстро: GoldenGate быстрее и стабильнее, но дороже на порядок. Если вы уходите с Oracle именно из-за цены, покупать GoldenGate — это крокодил, поедающий собственный хвост. Плюс с 2022 года Oracle-лицензии в России заблокированы санкциями, так что в нашем сегменте MSB у Debezium альтернатив фактически нет.
Схема данных: Liquibase и мини-таблица преобразований
До запуска CDC схему в PostgreSQL нужно подготовить. Копировать DDL вручную при 50+ таблицах — чистое мучение. Мы используем Liquibase с контекстами: DDL-чейнджсеты прогоняются сразу, DML отключаем до завершения первичной синхронизации — иначе они конфликтуют с потоком событий от CDC.
Ключевые преобразования типов Oracle → PostgreSQL:
| Oracle | PostgreSQL | Комментарий |
|---|---|---|
| NUMBER(1,0) | BOOLEAN | Если фактически используется 0/1 как флаг |
| NUMBER(precision,0) | INTEGER / BIGINT | По разрядности |
| NUMBER(p,s) | NUMERIC(p,s) | Для денег и дробных |
| VARCHAR2(n) | VARCHAR(n) | Но кодировка UTF-8, не cp1251 |
| CLOB | TEXT | Размер не ограничен |
| DATE | TIMESTAMP(0) | Oracle DATE хранит время, date в PostgreSQL — нет |
| BLOB | BYTEA | До 1 ГБ, или Large Object для больших |
| RAW(16) | UUID / BYTEA | Если это UUID — конвертируйте |
Отдельная головная боль — последовательности. Oracle SEQUENCE и PostgreSQL SEQUENCE работают по-разному: у NEXTVAL разная семантика. Мы всегда смотрим текущее значение в Oracle и сдвигаем Postgres с запасом вперёд:
-- На момент старта приложения
SELECT setval('users_id_seq', (SELECT MAX(id) FROM users) + 1000, false);Запас в 1000 нужен потому, что CDC может ещё догонять хвост, а приложение уже начало писать новые записи.
Конфиг Source: LogMiner и его ограничения
Минимально рабочий конфиг Debezium Source для Oracle — в реальных проектах он длиннее в 2–3 раза, но суть та же:
{
"name": "erp-oracle-source",
"config": {
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"database.hostname": "oracle-db.internal",
"database.port": "1521",
"database.user": "c##dbz_user",
"database.password": "${file:/run/secrets/oracle-pass:password}",
"database.dbname": "ORCL",
"database.connection.adapter": "logminer",
"log.mining.strategy": "online_catalog",
"log.mining.batch.size.default": "20000",
"table.include.list": "ERPUSER\\.ORDERS,ERPUSER\\.CUSTOMERS",
"topic.prefix": "erp",
"snapshot.mode": "initial",
"key.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"value.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"value.converter.apicurio.registry.url": "http://schema-registry:8080/apis/registry/v2"
}
}LogMiner вычитывает redo-логи Oracle и восстанавливает SQL-команды по изменениям. Это дорого по CPU на стороне Oracle — на нашей практике прод-сервер нагружался на 18–22% только от LogMiner, и клиенту пришлось временно добавить vCPU.
Альтернатива — XStream. Но он требует лицензии GoldenGate, которой у вас нет, раз уж вы уходите с Oracle.
Ограничения LogMiner, на которые натыкаются все без исключения:
- Имена объектов — строго до 30 символов. В Oracle 12c+ лимит подняли до 128, но LogMiner молча игнорирует длинные имена до сих пор. Сигнал в логах connect:
WARN Schema 'X' object name too long— таблица потеряна. - Неподдерживаемые типы. XMLTYPE, SDO_GEOMETRY, AnyData — LogMiner их не реплицирует. Выход: конвертировать в CLOB или переделывать архитектуру.
- ROWID не реплицируется. Если приложение использует ROWID как ключ (и такое бывает) — понадобится переписывать логику через SQL-миграцию.
- Supplemental logging обязателен. Без
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNSLogMiner не видит значения неизменённых колонок при UPDATE, и upsert на стороне PG ломается.
Avro вместо JSON — обязательная оптимизация
По умолчанию Debezium пишет в Kafka JSON с embedded schema. На одном из проектов уже в первые сутки мы получили Kafka-кластер, который задыхался: 3 ГБ в минуту, retention 7 дней — это 30 ТБ дисков. Клиент чуть не упал со стула.
Переход на Avro через Apicurio Schema Registry дал сжатие в 12 раз. Схема хранится в реестре, в каждом сообщении — только ссылка и данные. Результат: 250 МБ вместо 3 ГБ, кластер на 3 ТБ вместо 30 ТБ.
"key.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"key.converter.apicurio.registry.url": "http://schema-registry:8080/apis/registry/v2",
"key.converter.apicurio.registry.auto-register": "true",
"key.converter.apicurio.registry.find-latest": "true",
"value.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"value.converter.apicurio.registry.url": "http://schema-registry:8080/apis/registry/v2",
"value.converter.apicurio.registry.auto-register": "true",
"value.converter.apicurio.registry.find-latest": "true"Ещё один бонус — типизация. Реестр знает, что amount — это decimal(18,2), и JDBC Sink передаст правильный тип в INSERT. С JSON всё превращается в строки, и PG ругается на каждый коммит.
JDBC Sink: upsert, transforms и составные ключи
Типовой конфиг для записи в PostgreSQL:
{
"name": "erp-pg-sink",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"topics": "erp.ERPUSER.ORDERS,erp.ERPUSER.CUSTOMERS",
"connection.url": "jdbc:postgresql://pg-primary:5432/erp",
"connection.username": "erp_app",
"insert.mode": "upsert",
"delete.enabled": "true",
"primary.key.mode": "record_key",
"primary.key.fields": "ID",
"schema.evolution": "basic",
"database.time_zone": "Europe/Moscow",
"transforms": "unwrap,route",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.delete.handling.mode": "rewrite",
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.route.regex": "erp\\.ERPUSER\\.(.*)",
"transforms.route.replacement": "$1"
}
}Что делают трансформации:
ExtractNewRecordStateразворачивает сложный конверт Debezium (before/after/op/source) в плоскую запись, пригодную для INSERT.RegexRouterприводит имена Kafka-топиков к именам таблиц:erp.ERPUSER.ORDERSпревращается вordersв PG.- При DELETE режим
rewriteпомечает запись tombstone, и SinkConnector выполнитDELETE FROM orders WHERE id=?.
Составные ключи задаются через "primary.key.fields": "COMPANY_ID,ORDER_ID". Работает, но проверяйте тщательно — Debezium не всегда правильно восстанавливает порядок полей ключа.
Реальный кейс: миграция биллинга за 11 недель
В июле 2025 года к нам пришёл оператор связи из нескольких регионов ЦФО — до 50 административных офисов, около 12 000 абонентов бизнес-сегмента. Биллинг на Oracle 12c Standard, 14 микросервисов на Spring Boot, 620 таблиц, 1.4 ТБ данных. Причина простая: продление лицензии Oracle стоило 4.8 млн рублей в год, а продавец отказался её возобновлять из-за санкций.
Работали вчетвером от нас: два бэкенда, один DBA, один сисадмин — это я. Со стороны клиента подключился ещё один инженер.
Последовательность:
- Недели 1-2. Инфраструктура: Kafka-кластер на трёх брокерах с NVMe и сетью 10G, PostgreSQL HA через Patroni, мониторинг в Zabbix и Grafana.
- Недели 3-4. Подготовка схемы через Liquibase, DDL-чейнджсеты прогнаны в dev. Написали скрипт валидации: сравниваем
COUNT(*)по всем таблицам Oracle и PG. - Неделя 5. Debezium на staging: поток 6 000 событий/сек, стартовая синхронизация 320 ГБ заняла 3 часа 40 минут.
- Недели 6-10. Мигрировали микросервисы от простых к сложным. Каждый запускали в новом namespace с подключением к PG, переключали трафик через балансировщик по feature toggle. Первым пошёл сервис уведомлений как тест, последним — биллинг-ядро.
- Неделя 11. Финал: Oracle переведён в readonly на 30 дней для возможного отката, Debezium-коннекторы удалены, итоговый дамп снят.
Итог: 11 недель, ноль инцидентов, клиент полностью ушёл с Oracle. Стоимость проекта — 2.1 млн рублей. Экономия в первый год — 2.7 млн (4.8 лицензия минус 0.9 на поддержку PostgreSQL и железо). Окупилось за 10 месяцев.
Где мы наступили на грабли
Честный перечень проблем, каждая из которых стоила от дня до недели:
- DELETE-шторм замедлил лаг. Один сервис раз в сутки удалял 2 млн строк массовым DELETE. Debezium Source выплёвывал 2 млн событий подряд, Sink давился JDBC-операциями по одной строке. Заменили DELETE на soft-delete — обновление флага
is_deleted. Лаг упал с 90 минут до 8 секунд. - Таблица без PK. Лог-таблица на 400 млн строк без первичного ключа. В режиме upsert Debezium отказывался писать вообще. Добавили суррогатный PK:
ALTER TABLE ADD COLUMN id BIGSERIAL PRIMARY KEY— час работы. - Connection pool PG зависал. На пиках Debezium открывал больше 200 соединений и накапливал ожидающие транзакции. PGBouncer это не пережил. Выставили
max.retries: 3,connection.pool.max: 20иretry.backoff.ms: 5000. - Имена в верхнем регистре. Oracle хранит имена в UPPERCASE, PG по умолчанию — нижний регистр. Решили через
transforms.routeсtoLower. - Часовые пояса. Oracle хранил TIMESTAMP без TZ, и приложение считало, что это Europe/Moscow. PG по умолчанию — UTC. Настроили
database.time_zone: Europe/Moscowв Sink.
Чек-лист перед продакшеном
- Supplemental logging включён на Oracle — на уровне DATABASE или TABLE.
- У пользователя Debezium есть права
SELECT ANY TRANSACTION,LOGMINING,SELECT ON V_$ARCHIVED_LOG. - Kafka retention — минимум 7 дней: нужен запас, чтобы пережить перезапуск коннектора.
- Все последовательности PostgreSQL сдвинуты вперёд с запасом.
- Скрипт валидации
COUNT(*)и выборочных SHA256-сравнений строк запускается автоматически. - Мониторинг Debezium в Grafana — алерт на lag > 60 секунд настроен и проверен.
- Документ «Как откатиться за 15 минут» с конкретными шагами проверен на staging, не на бумаге.
- Oracle остаётся живым минимум 30 дней после переключения на PostgreSQL.
Мигрируем с Oracle на PostgreSQL без простоя — от 1.5 млн
Я лично веду проекты миграции баз данных для среднего бизнеса в Москве и области. Debezium + Kafka + PostgreSQL, последовательная перепрошивка микросервисов, контролируемый откат. Типовой проект — 8-14 недель при 8-15 микросервисах и объёме до 2 ТБ. Предварительный аудит инфраструктуры бесплатно, расчёт и план — за 3 рабочих дня.
Телефон: +7 903 729-62-41
Telegram: @ITfresh_Boss
Семёнов Евгений Сергеевич, директор АйТи Фреш
FAQ — миграция Oracle → PostgreSQL
- Почему Debezium, а не Oracle GoldenGate?
- Debezium — Open Source, бесплатный и проще в развёртывании. GoldenGate стоит дорого и покрыт санкциями с 2022 года. Для большинства бизнес-сценариев Debezium LogMiner покрывает все задачи CDC с лагом в несколько секунд.
- Сколько длится миграция микросервисной системы?
- Зависит от объёма и количества сервисов. Наш клиент с 14 микросервисами, 620 таблиц и 1.4 ТБ данных в Oracle завершил миграцию за 11 недель, перенося по 1-2 сервиса в неделю. Стартовая синхронизация тяжёлых таблиц занимала 3-5 часов.
- Как бороться с большим объёмом JSON в Kafka?
- Переключайте Debezium на Avro через Apicurio Schema Registry. Мы получили сжатие в 12 раз: 3 ГБ топика с JSON превратились в 250 МБ Avro. Это критично при нагрузке свыше 50 сообщений в секунду.
- Что делать с таблицами без первичного ключа?
- Debezium JDBC Sink в режиме upsert требует PK. Варианты: добавить синтетический PK в целевой БД, переключиться в insert mode (без обновлений) или использовать уникальный индекс. Последний вариант рискован при дубликатах.
- Как откатиться, если на проде всё сломалось?
- Перед переключением приложения на PostgreSQL сохраняете дамп Oracle в текущем состоянии и не отключаете редо-логи минимум неделю. Если что-то пошло не так — переключаете приложение обратно на Oracle. Dual-write даёт ещё более безопасный откат, но удваивает сложность.